Cheating At Monopoly
Forget private-sector innovators; examining the state’s role in creating the Internet and mobile tech…
Whenever fresh waves of scandal crash into Big Tech, its defenders reliably bring up the cutting-edge technology itself. Sure, they may be incredibly powerful, but hey they earned it—Gates and Jobs and Bezos and Zuckerberg had to invent the technology that made them rich, right? Say what you want about our private sector innovators, at least the private sector brings us wondrous innovations in the first place.
Except, of course, that the original name for the Internet was ARPANET, because it was developed by the U.S. military’s research arm and affiliated universities. The original address of Google was not google.com but google.stanford.edu, because it was developed in a publicly-subsidized research campus. The original Wi-Fi network was ALOHAnet, because the U of Hawaii struggled to network its island campuses and developed new radio technology to do it.
In fact, nearly all the scientific and engineering research that went into today’s fancy high-tech products and services came from the public sector—primarily the research universities and the military system. Vanessa Bee observed in these pages that capitalism can in fact constrain innovation, as workers alienated from management may not wish to jeopardize their jobs by reporting ideas for innovations, since disruption often means cutting payroll. And the near-term pressure to turn innovations into new profitability closes off many promising but perhaps slower research channels, leaving basic R&D in decline. She notes that public institutions are naturally better at long-term research, where creators are free to experiment without the short leash of a corporate overseer.
Even a very brief review of modern tech history proves the case, and helps us see where resources are best used to develop the science and technology of the future. It also shows where the credit really belongs for today’s enormous online platforms, which host all our shallow lifestyle posts, hyper-partisan bickering and delightful cat videos.
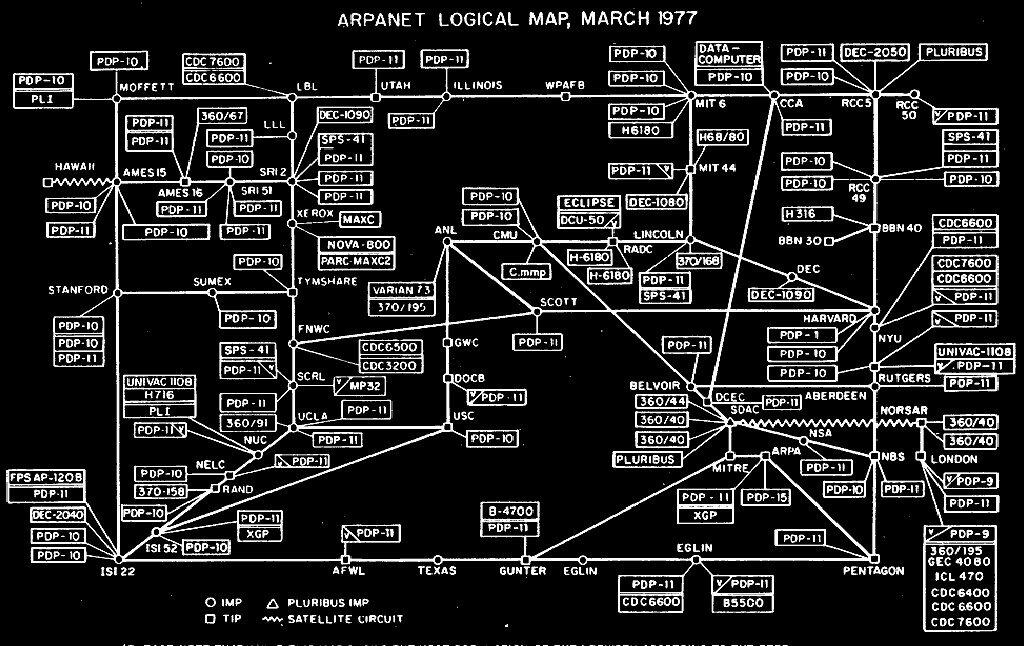
The Advent of ARPANET
Consider the Internet and its most popular application, the World Wide Web. The system that would become the Internet first arose in the 1960s in response to multiple needs of federal agencies: a desire by scientists to share access to then-scarce computing resources, and the U.S. military’s need for a decentralized, redundantly-connected network that could survive a Cold War nuclear blast, and information management to handle the global U.S. spying network. The project was taken up by ARPA, the Advanced Research Projects Administration, the Pentagon’s main research arm.
The technology to provide both these goals was eventually found in “packet switching,” a means of sending information in which a message or data is broken down into packets with address information attached, sent through a communication network and reassembled at its destination back into the original message. This technology had costs from having to include routing info on so many packets, but it made the system flexible and allowed for cheaper hardware.
ARPA funded the leasing of communication lines from the then-monopolist of U.S. telecommunications, AT&T, and organized the project. The first ARPANET computing installation to be connected was UCLA in September 1969, followed by the other early network nodes of UC Santa Barbara, the University of Utah, and the Stanford Research Institute (SRI). A good deal of technical details had to be painstakingly ironed out, yet decisions were mostly made through a consensus process among users and operators, and ARPA’s funding gave it the ability to coerce holdouts.
Even in the early days of limited network use in the 1970s, user activism was common, including in the Users Interest Working Group (USING), which lobbied for more applications funding and other issues. But as Janet Abbate observes in her essential book Inventing the Internet:
Faced with organized action by users, the ARPA managers were evidently afraid that the network might slip out of their control. Members of USING were dissuaded from pushing their demands by ARPA program manager Craig Fields, who made it clear that the authority to make plans for the network lay with ARPA, not with USING…The fate of USING revealed the limits of ARPA’s generally non-hierarchical management approach. Individual users or research teams had tacit or explicit permission to add hardware and software to the system; ARPA even gave financial support for some of these experiments. However, users as a group had no say in the design decisions or funding priorities of the ARPANET project. The ARPANET experience is a reminder that the efforts of individuals to build virtual communities are constrained by the realities of money and power that support the infrastructure of cyberspace.
More and more scientists were using ARPANET to transmit data sets and gain access to computing power, analyzing seismic and weather data, modeling molecules, and advancing medicine. And packet-switching technology was being applied to other communications media, so by the 1970s ARPA was running three experimental networks—the wired ARPANET, the Bay-area radio-based PRNET, and the satellite-based SATNET.
It was only when ARPA successfully demonstrated interconnection of these different network systems that the Internet could be born. This would require devising technology for connecting them, called protocols, which had to be designed to run on many different computers and allow for an orderly flow of data between hosts. The solution, after prolonged design debate under ARPA’s aegis, was a set of protocols knowns as the Transmission Control Protocol and Internet Protocol (TCP/IP), with the former arranging the flow of packets and the latter managing the articulation among the different networks. TCP/IP was well-suited for the military, which eventually adopted it and thus gave it a great impetus to spread as an informal standard.
Importantly, ARPA insisted the protocols, as well as source code for the computers connecting the ARPANET, and other crucial information be publicly available and not the property of its primary contractors. And as Abbate comments, “Beyond [cutting-edge research center] Xerox PARC…there seems to have been no corporate participation in the design of the Internet.” And as the excellent Misunderstanding the Internet recounts “Indeed, in 1972 the telecommunication giant AT&T declined the government’s offer to take over ARPANET, the forerunner of the modern internet, on the grounds that it was not likely to make a profit.” IBM also turned it down.
So it was ARPA that made the triumphant demonstration of the Internet, a network of networks, when on November 22, 1977 packets of data were broadcast from a traveling van on a California highway with PRNET, to an ARPANET gateway, into space through SATNET to Europe, and back via ARPANET to California. This proof of concept excited the technical community and spurred interest among many research and defense bodies, which joined the network and adopted its open protocols, often with ARPA help or funding. In time the military insisted that all ARPA sites adopt them, which meant long hours reconfiguring host computers, but helped further the technical standards required for internetworking. The military also segregated its network (MILNET) off from ARPANET in 1983, putting the latter under civilian control and bringing university researchers back into dominating its user base.
Inventagon
In the early 1980s, the Internet grew as many more universities were connected to ARPANET via their computer science departments’ phone line-based connections, mainly through funding from the National Science Foundation (NSF), the major U.S. basic research supporter. ARPA helped finance these local area networks too, while the NSF helped bring large regional networks of universities online, and leased high-speed lines for a “backbone,” a central network to manage the rising packet switching traffic. This NSFNET overlapped with ARPANET for a time and shared costs, but by the time most universities were networked in the late 1980s the ARPANET was showing its age. 20 years is a long interval in computer science terms, and military overseers decided to retire it as obsolete, transferring the ARPANET nodes to the NSFNET, formally dismantling the former in February 1990.
As usage climbed, US telecom companies finally began taking an interest and pressure rose to privatize the network, as private investment in commercial networks for companies, schools or individuals had gradually spread in the wake of the pioneering ARPA and NSF networks. By the early 1990s, it became possible for the commercial spinoffs of the early contractors to take over as “a whole parallel structure of commercial TCP/IP networks had evolved.”
Considering the usual story of online tech arising from brilliant small business startups, it’s hilarious that Colonel Heidi Hedien ordered commercialization of the technology, for the nominal reason that there would be multiple commercial suppliers of the networking tech. This included a $20 million fund for computer manufacturers to port TCP/IP to their products, which Abbate openly calls “technology transfer,” a phrase better known in this era for condemning Chinese government requirements that Western companies share tech secrets in exchange for access to China’s giant market. But this current technology being forcibly transferred relies on tax-funded work forked right over to the business world decades ago, and they were paid for the privilege.
Indeed, Abbate’s own rather conservative book’s summary leaves the conventional view dead in the water:
The story of the Internet’s origins departs from explanations of technical innovation that center on individual inventors or on the pull of markets. [ARPANET and packet-switch designers] were neither captains of industry nor ‘two guys tinkering in a garage.’ The Internet was not built in response to popular demand, real or imagined; its subsequent mass appeal had no part in the decisions made in 1973. Rather, the project reflected the command economy of military procurement, where specialized performance is everything and money is no object, and the research ethos of the university, where experimental interest and technical elegance take precedence over commercial application.
The lone garage-tinkering disruptive startup is such a widely-held trope that even the most conspicuously suspicious frauds can get away with it, as long as they act like Steve Jobs.
Under the NSF’s 1991 privatization plan, Internet service would be taken over by market firms, including some of the phone and cable companies, to be designated as Internet Service Providers (ISPs). The ISPs would provide better service and investment than government bodies since they were to compete and provide their own gateways among their network backbones. The transfer from NSFNET to commercial ISPs was effected on April 30, 1995, marking the end of U.S. government ownership of the Internet’s systems and infrastructure.
But the cable ISPs went on a massive merger binge after deregulation under the Telecommunications Act of 1995, becoming the cell phone oligopolists and the great regional monopolies like Comcast and AT&T. So while the loss of control by the authoritarian military may sound appealing, the history comports with the main message of the authors of Misunderstanding the Internet, who found that early optimistic forecasts of the Internet’s potential “all had one enormous error at their center. They failed to recognize that the impact of technology is filtered through the structures and processes of society…In brief, the rise of the internet was accompanied by the decline of its freedom.”
After privatization came the rise of the Web—but not due to corporate innovation. Tim Berners-Lee is famous for developing the three main technologies that constitute the standard protocols needed for any user to get on the Web and view information. Working at the giant particle accelerator at CERN, with an enormous amount of technical equipment for testing fundamental particles, he developed a “memory aid” that allowed the creation of documents where words could be clicked, leading to other documents explaining the term. This became “hypertext” and Berners-Lee pioneered the acceptance of a decentralized protocol system for it. This meant some links could become “dead,” but the system would be open to independent users.
Then came the encoding language (HTML) and the system for creating addresses for various sites and pages, the universal resource locator URL. Berners-Lee also set up and wrote the software for the first computer “server” that made documents available to online users. Crucially, CERN had adopted TCP/IP, so the Web could run on top of those protocols and be used by any user connected to the ARPANET/NSFNET.
Fascinatingly, in addition to the military’s failed attempts to get private corporations to take over the early Internet, there was a private market-based attempt for global hypertext systems similar to that created at CERN. Engineer Ted Nelson developed a project called “Xanadu,” but as the press recounts, “Nelson wanted Xanadu to make a profit, and this vastly complicated the system, which never got off the ground. Berners-Lee, in contrast, persuaded CERN to let go of intellectual property to get the Web airborne.” Berners-Lee has since indicated his concern that the World Wide Web’s potential has been undermined, quoted in Eli Pariser’s The Filter Bubble saying “Some of its most successful inhabitants have begun to chip away at its principles. Large social-networking sites are walling off information posted by their users from the rest of the Web…the Web could be broken into fragmented islands.”
Mobilizing for Mobile
Let’s turn to Wi-Fi, the modern world’s favorite thing to both use and complain about. The local radio signals that allow mobile computing within range of a router at home or business are the principal means of Internet access today, and perhaps unsurprisingly it was invented by a research university. Tech journalist Brian Merchant writes “While wireless cell networks evolved from massive government-backed projects, the main way our phones get online began as a far-flung academic hackaround. Wi-Fi began long before the web as we know it existed and was actually developed along the same timeline as ARPANET.” In the ’60s, the U of Hawaii’s various island labs couldn’t communicate with the main computer in Honolulu. Using a pair of high-speed UHF channels to access computing resources, “The project would grow into the aptly named ALOHAnet, the precursor to Wi-Fi.” The project was also partially funded by ARPA and the U.S. Navy.
Meanwhile, although Apple is the tech giant most associated with slick mobile technology, it arguably owes the most to public research. The famously sensitive multi-touch interface of the iPhone and later smartphone and tablet models owes an enormous amount to public research, despite Jobs’ claim at the original launch to have originated the technology, “And, boy, have we patented it.” Amazingly, the first screen surface able to detect multiple simultaneous finger movements was developed in the 1970s by an engineer at CERN, the same particle collider complex where Berners-Lee would later develop the Internet Protocols.
Merchant notes that “while Jobs publicly claimed the invention as Apple’s own, multi-touch was developed decades earlier by a trail of pioneers from places as varied as CERN’s particle-accelerator labs to the University of Toronto to a start-up bent on empowering the disabled. Institutions like Bell Labs and CERN incubated research and experimentation; government poured in hundreds of millions of dollars to support them.” The touch-sensitive “capacitive screens” themselves, which take advantage of the human body’s own ability to conduct electricity, arose in research by the Royal Radar Establishment, a U.K. military body, in the 1960s. The highly versatile multitouch interface itself, allowing many different commands and actions from the user, was developed by a U of Delaware PhD candidate under an NSF-CIA research program. He later commercialized the technology, and his company was bought by Apple in 2005, two years prior to the first iPhone release.
The overall innovation process was especially well-described by a government report from the conservative Bush years, by the science-promoting body the Office of Science and Technology Policy, which in a February 2006 report on digital technology analyzed the iPod, Steve Jobs’ celebrated smartphone predecessor. It itemizes the important components, from the drive to the memory to the battery, and documents their development through public-sector research. The complex LCD display was the result of research from the Defense Department, National Science Foundation and the National Institutes of Health; basic research on processing radio signals was funded by the Army Research Office; the DRAM memory cache was developed by IBM with DARPA funding. The report concluded that the iPod “illustrates the unexpected benefits of basic research…The device itself is innovative, but it built upon a broad platform of component technologies, each derived from fundamental studies in physical science, mathematics, and engineering.”
But The Entrepreneurial State by Mariana Mazzzucato is by far the best consideration of all these issues, including the origins of the smartphone era. She observes that what fundamentally makes a smartphone smart is its connection to the Internet and other online applications, which as we’ve seen rely completely on the networks created and nurtured over many years by ARPA and the NSF. But further, the Global Positioning System required for Google Maps and finding local resources was developed by the DoD in the 1970s for more accurate deployments of material and munitions. Only in the 1990s was it released and quickly swamped with civilian use.
The attractive liquid-crystal displays, too, owe their existence to Cold War military investments, spurred by worries that dominant Japanese display suppliers lacked adequate capacity to meet U.S. demand alone. So the Pentagon organized an industry consortium working on flat panel displays, with the breakthrough technology under development at manufacturer Westinghouse. Mazzucato notes that “The research carried out at Westinghouse was almost entirely funded by the US Army.” But the company then shut down the program, leading the project head to appeal to a series of US computer giants—IBM, Compaq, Xerox, 3M, and was turned away by all of them until he received a contract from ARPA in the late eighties. Further, the lithium-ion batteries essential to today’s power-hungry devices have a similar story of early funding from the NSF and the Department of Energy. And cellular communications standards, and the early system development to prove the concept, were heavily supported by European government investments in signal processing.
And so on. Jobs sure was proud of his role in designing the device, but his engineers relied on decades of taxpayers funding these research agencies whose investments created all the fancy tiny components of the slick device you use to text your friends and take pictures of your pets.
iPhonies
And beyond the fundamental Internet and Web networks, even the technologies at the hearts of the Big Tech online platforms themselves often derive from public work. Bill Gates’ and Paul Allen’s original BASIC-MS operating system, which they sold to IBM and ended up dominating the global market for many years, was written in the BASIC computer language. This language was created by professors at Dartmouth in 1964 with funding from the National Science Foundation. Later Gates was filled with scorn that the public might oppose his use of this technology to utterly monopolize computing.
And beside the background to smartphone multi-touch interfaces, Apple had even more fundamental roots in public-sector technology. The PARC research facility, from which Steve Jobs obtained the basics of the Graphic User Interface that became the Mac and eventually all computer interfaces, had several former ARPA researchers working on those display concepts. The prominent Wired journalist Steve Levy wrote, “This little-known branch of Defense was quietly kick-starting the computer revolution that would result in the Macintosh.”
The most visionary action that can be contributed to the world’s richest man, Amazon’s Jeff Bezos, is that in the Web’s early days he was “doubling and tripling his bet on the Internet,” as his biographer puts it. A wily business move perhaps, but it amounts to recognizing a good opportunity to make money on technology developed by federal taxpayers over the 1960s, ’70s and ’80s. Meanwhile, Facebook’s deferential corporate biographer David Kirkpatrick wrote “Something like Facebook was envisioned by engineers who laid the groundwork for the Internet. In a 1968 essay by J. C. R. Licklider and Robert W. Taylor ‘The Computer as Communication Device,’” the two essentially envisioned Facebook’s basic social network. They worked for ARPA.
And of course Google itself, considered the most academically-inspired of the megacap tech behemoths, was originally google.stanford.edu. There it was developed by taxpayers of the U.S. and the State of California, with the long-term research stability of a major research institution and freedom from the need to turn a short-term dollar. There, Page and Brin could state with detachment in an early research paper still viewable online, that “advertising funded search engines will be inherently biased towards the advertisers…We believe the issue of advertising causes enough mixed incentives that it is crucial to have a competitive search engine that is transparent and in the academic realm.” Obviously they got over that, as Google has played the leading role in covering the Internet with ugly, slow-loading, brain-eroding eyesore advertisements. (And was eventually fined $2.7 billion by the European Commission for illegally favoring its comparison-shopping services at the expense of competitors.)
Google’s search algorithms have been hugely elaborated since it became a private company, of course, but once in the realm of the marketplace technology evolves only in directions that engorge profitability. Data scientist Cathy O’Neil’s distressing and digestible book Weapons of Math Destruction reviews harmful software algorithms, ones with no transparency or dynamic learning to improve on known previous errors. She notes that “In the case of web giants like Google, Amazon, and Facebook, these precisely tailored algorithms alone are worth hundreds of billions of dollars,” yet:
Our livelihoods increasingly depend on our ability to make our case to machines. The clearest example of this is Google. For businesses, whether it’s a bed-and-breakfast or an auto repair shop, success hinges on showing up on the first page of search results. Now individuals face similar challenges, whether trying to get a foot in the door of a company, to climb the ranks—or even to survive waves of layoffs.
O’Neil also notices that these harmful algorithms “tend to punish the poor…The privileged, we’ll see time and again, are processed more by people, the masses by machines.”
A similar story emerges with artificial intelligence, considered among the most advanced technological fields today, with origins again in public research. Merchant observes that “Before Siri was a core functionality of the iPhone, it was an app on the App Store launched by a well-funded Silicon Valley start-up. Before that, it was a research project at Stanford backed by the Defense Department with the aim of creating an artificially intelligent assistant.” That includes the spoken interface so associated with AI in the popular imagination. “As with much of the advanced computer research around Stanford then, ARPA was doing the funding. It would mark a decades-long interest in the field of AI from the agency, which would fund multiple speech recognition projects in the 1970s.”
The field is advancing based on deep neural networks—computer algorithms modeled on the human brain that crunch data and attempt to learn to do different tasks. These most elaborate algorithms, however, will be corporate property, and the companies will resist divulging their proprietary code just as they already do for more conventional algorithms that sort search results and screen loan applicants. The conservative Wall Street Journal observes “For the corporations, the algorithms will be proprietary tools to assess your loan-worthiness, your job applications, and your risk of stroke. Many balk at the costs of developing systems that not only learn to make decisions, but that also explain those decisions to outsiders.”
This likely means a powerful new tool will gradually emerge for the tech giants, and be developed as recklessly as the rivalry among the monopolists allows. The industry has tried to pre-empt serious government regulation by creating a number of proposed ethical guidelines, but it’s unlikely these entities will propose anything that could limit their future profitable exploitation of the technology they’re investing in today. So far U.S. administrations have been willing to allow self-regulation and these guidelines are evidently intended to perpetuate that permissiveness.
There are institutional reasons that major technological leaps are so often made by publicly-backed research entities rather than private companies. Only states and publicly-funded research institutions can support long-term basic scientific research, which by its nature is based on exploring the unknown and is never sure of any breakthrough, let alone a money-making one. Plus, scientific research and experimental engineering are expensive, with costly professionals like trained scientists and fancy research and prototyping equipment.
Private institutions are under systemic and legal obligations to make money quickly to reward their capitalist investors, and expensive, uncertain long-term research is inevitably harder and harder to justify as quarters tick by with few money-making breakthroughs to show for it. A partial exception exists if a company is somewhat insulated from market pressures by monopoly power, like Google and the other megacap platform companies. With these market incentives against research, no wonder then that the Internet, the Web, the GUI, modern processors, Wi-Fi signaling, fundamental computer languages and even Google itself arose from the academic or military research settings, where steady funding is more or less assured and near-term stock prices don’t drive whether projects get axed. Bee observes that “innovation in this area is less motivated by extracting profit, and more so by signifiers of prestige, career appointments, recognition, publication, project funding, and prizes.”
The history is long—Marconi developed radio for the Royal Navy, Berners-Lee the Web protocols for CERN. The OSTP notes “Past DoD research has resulted in revolutionary technological capabilities such as radar, digital computers, wireless mobile communications, lasers, fiber optics, composite materials, the Internet (and other ‘packet switched’ networks), and satellite navigation.” Mazzucato observes that private businesses dominate overall spending on research and development (R&D), responsible for 67 percent of the total. However, on basic R&D, studying subjects with no immediate commercial value and sometimes discovering basic new technologies, the federal government together with the university system hugely dominate at 72 percent.
The point of course isn’t that the military should have discretion on where it spends its hundreds upon hundreds of billions of dollars each year, or that the warped pitiless nightmare of modern war is worth it for its high-tech spinoffs. The point is that the public setting is the natural space for scientific and technological research, providing the funding, managing the long-run research uncertainty, and maybe imposing some publicly-demanded constraints on what can be done with the tech.
Not only is technology too important to be left to the technology industry, it didn’t even come from them in the first place. A movement for online socialism would demand that the crucial platforms be socialized—brought under the control of the people who run them and make them successful—the engineers, phone industry workers, and all of us content creators. We could decide democratically the broad direction of future research, the limits to use of our personal data, and use the potential of the Internet for its most positive educational and fulfillment possibilities. And we could tell the 1% just what the fucking Terms of Service are.




